Intro to Collaborative Editing
An initial exploration of collaborative editing and conflict-Free replicated data type
 Collaborative Editing Demo
For live demo, please play at here.
For source code, please visit here
Collaborative Editing Demo
For live demo, please play at here.
For source code, please visit here
Introduction
Collaborative editing systems are everywhere in our life. Google Docs and Microsoft Office 365 are most represented products. On wider definition, Dropbox and Github have similar functionality.
These systems allow multiple users to view and edit the same document at the same time without disturbing each other. Most systems adopt a replicated architecture for the storage of shared documents. For each update it is executed on the local replica immediately after its generation and then be broadcasted to remote replicas. Consistency maintenance is one of the most significant issues in designing and implementing of such systems.
This blog is going to talk about the technologies behind, especially on two mature solutions for collaborative editing -- operational transformation and conflict-free replicated data types.
Eventual Consistency
Imagine users are connected by weak network or even no connections, how could people still work together? Now let's introduce eventual consistency[EC], as its name implies, eventually, all replicas will get all updates and reach the same state.
EC is a weaker consistency model compared to strong consistency[SC]. Unlike SC, which uses consensus algorithms[eg. Raft, Paxos] to enforce the total order updates for all replicas, EC guarantees that eventually all replicas will reach the same state after people stop updating. EC provides higher availability and lower latency by allowing local updates on each replica. During conflicts reconciliation, replicas could use Lamport lock or vector clock to arbitrate or rollback.
Strong eventual consistency[SEC] is a subset of EC, which provides a deterministic outcome of concurrent updates without conflicts and rollback. Remember CAP[Consistency, Availability and Partition Tolerance] theorem, people proved that we could only achieve two of three at the same time. If we make SEC our consistency model, then now all three could be satisfied. CRDTs is the common approach to SEC and we will talk about it later.
Operational Transformation
Operational Transformation[OT] is a technology used in collaborative editing, mostly to solve intention violation, which means the actual effect of an operation at the time of its execution may be different from the intended effect of this operation at the time of its generation because of concurrent generation of operations. Google Docs is the most famous product using OT.
History
Applying OT to maintain consistency in real-time collaborative editing systems was pioneered by Ellis and Gibbs in the GROVE system in 1989. The GROVE system used the distributed operational transformations (dOPT) algorithm for transforming independent operations. Essentially, the dOPT algorithm adopted an inclusion transformation strategy. The basic idea was to perform the inclusion transformation on each causally ready operation against all executed independent operations in the Log in the order from the oldest to the most recent. But dOPT is not completely correct. Following dOPT there are also some algorithms proposed to improve the OT implementation like adOPTed algorithm proposed by Ressel in 1996. GOTO aims to optimize the GOT algorithm by reducing the transformation of insertion and deletion. Jupiter is another algorithms proposed by Nichols in 1996, which is the foundation of many modern collaborative system like Google Docs, Etherpad, and Wave.
Description
Suppose an operation is generated on the site 1 without any knowledge of another operation
generated on the site 2 at the same time. Since both operation are based on the same coordination system while the operation may accompanied by the position update, if the two operation execute the original operation independently it will violate the original intention. OT is designed to transform the second operation based on the first operation since the first operation may cause the position update.
As a result we can come to a more formal description of OT: suppose operation is generated on site 1 while at the same time
is generated on site 2, in order to achieve consistency on both site 1 and site 2 have to execute
and
. For site 1 its operation order is
followed by
which can be denoted as:
while for site 2 its operation order is followed by
which is denoted as:
What we want is the final outcome of the two operations on both site are the same namely we want:
If we execute the original operation the above equation will not stand. OT will do transformation on the second operation on both site to make the above equation stand which can be denoted as:
Analysis
With OT we could have a lock-free system. OT optimistically assumes that whatever operations are currently being applied to the document on any given client will not be conflict with any operations that might be applied at this same moment by other clients. Conflicts can't be discovered, let alone dealt with, until some point in the future. As a result there is no need to request a lock on the document from the server.
The disadvantage is the overhead of transformation. Each update on the previous operation requires all the following operations to update.
Conflict-free Replicated Data Types
An alternative solution is to use conflict-free replicated data types[CRDT], which is a way newer technology compared to OT.
History
CRDT first appears in 2006. WOOT is an algorithm for managing cooperative editing, where each character has a unique identifier. The drawback is the data structure will grow indefinitely, because there is no garbage collection for meta data. Roh et al. proposed the CRDT approach using the example of an array with a slot assignment operation. They propose a deterministic procedure[based on vector clocks] to make sure one operation is after another. Similar to last-write-wins, this approach does not consider the case of co-operative editing, thus concurrent updates will not be merged, but lost. Treedoc is proposed using dense binary tree to represent the document. Later, Weiss et al. proposed the Logoot, which uses a sparse n-ary tree. A position identifier is a list of non-integer unique identifiers, and Logoot does not flatten. Logoot has a high overhead compared to Treedoc. There is a newer approach for list-based CRDT. CRDTs are also widely used for registers, counters, maps and sets.
Description
Two fundamental approaches are used to propagate updates among replicas - state-based replication and operation-based replication.
- State-based approach
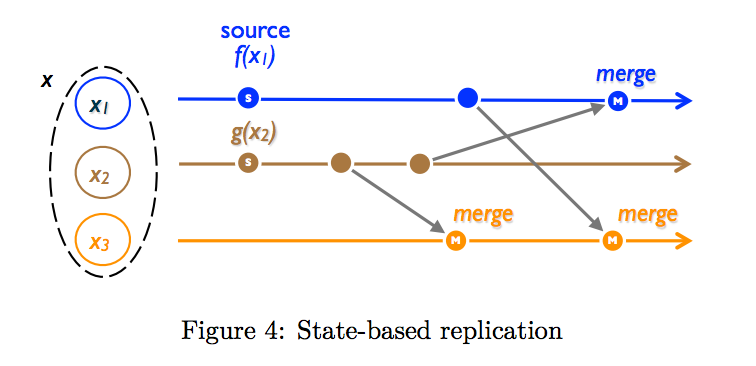 State-based replication approach
source.
State-based replication approach
source.
After local updates, each replica sends its full state[payload] to others. On receive, each replica merges with its own full states.
The sufficient condition for convergence is -- payload type should forms a monotonic semi-lattice and computes Least Upper Bound then replicas converge to LUB of last values. This requires that updates are always increasing. An object satisfying this condition is called a Convergent Replicated Data Type[CvRDT].
The drawback is the overhead of sending all states.
- Operation-based approach
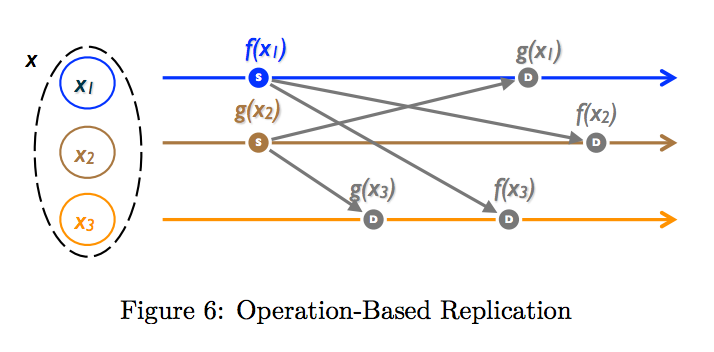 Operation-based replication approach
source.
Operation-based replication approach
source.
After local update, each replica broadcasts to all replicas. Then other replicas replay the operations received.
The sufficient condition for convergence is -- all concurrent operations should commute because they could arrive in any order. An object satisfying this condition is called a Commutative Replicated Data Type[CmRDT].
Any state-based model could be converted to operation-based model. We could also combine these two models and it will remain CRDT.
Example: A Conflict-free Counter
This is a multi-master counter using state-based approach, two arrays are representing the incrementing/decrementing for each replica.
During increment and decrement operations, just change the corresponding value in two array. Enforcing increasing could guarantee the partial order.
At the end to the day, the overall values will be the delta of two summations.
Each time, a replica will send two arrays to other replica and each replica should only modify one index. On merge, we will get max of a certain location.
A list-based CmRDT
This section will introduce the model used in the demo. This work is based on this and this. Assume and
are two replicas. They have the initial state like follows
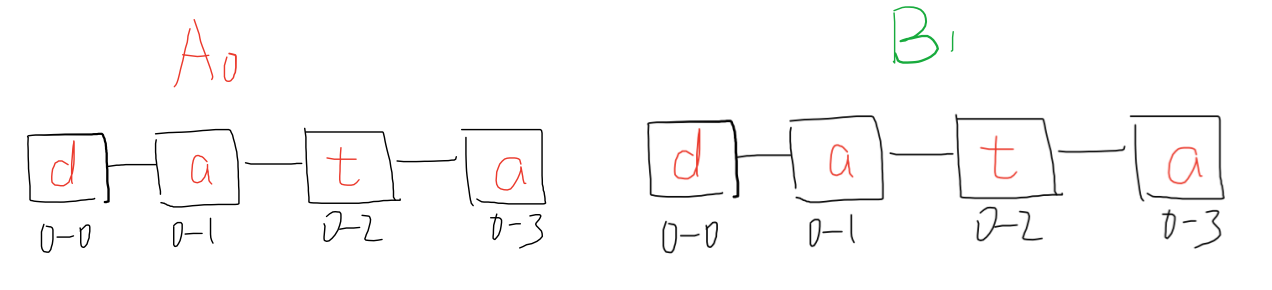 Initial state
Initial state
The identifier of each character is replica_id-character_NO. where replica_id is unique through all replicas and character_NO. of a inserted character will always be greater than the existing maximum character_NO..
- Insertion
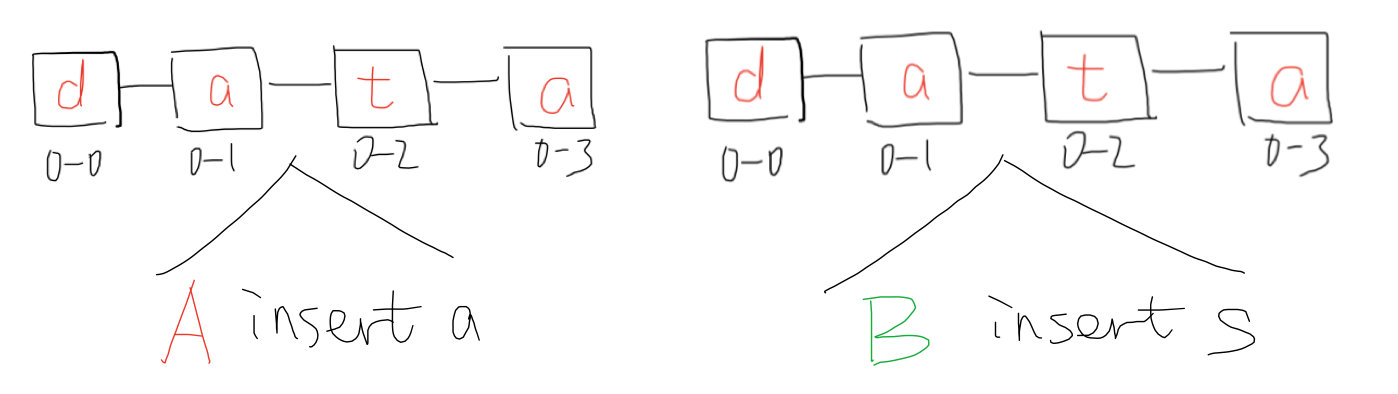 Insertion step 1
Insertion step 1
 Insertion step 2
Insertion step 2
Then each replica insert a character locally.
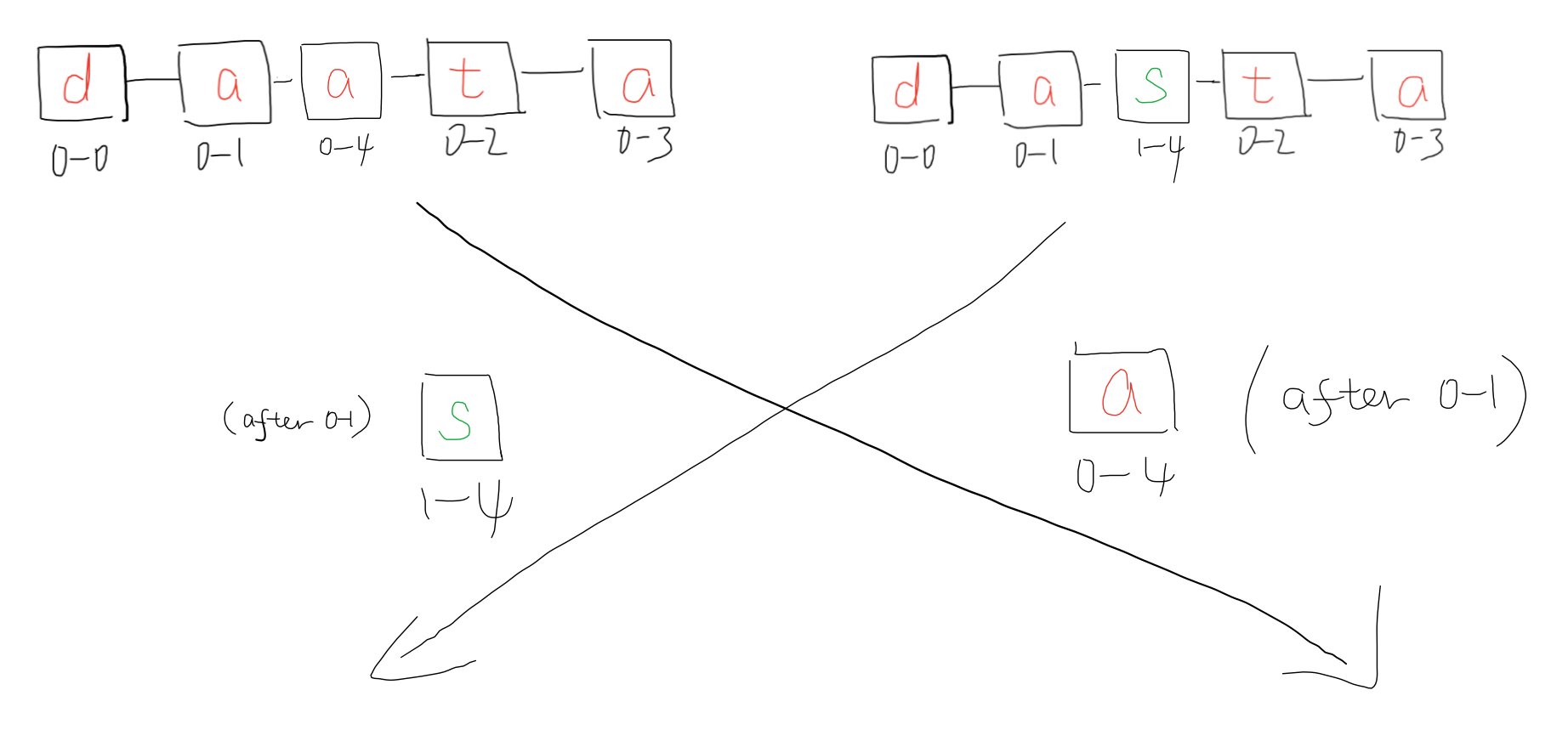 Insertion step 3
Insertion step 3
And the updates are sent to the peers. Note that we are basing on the unique identifier of previous character rather than location.
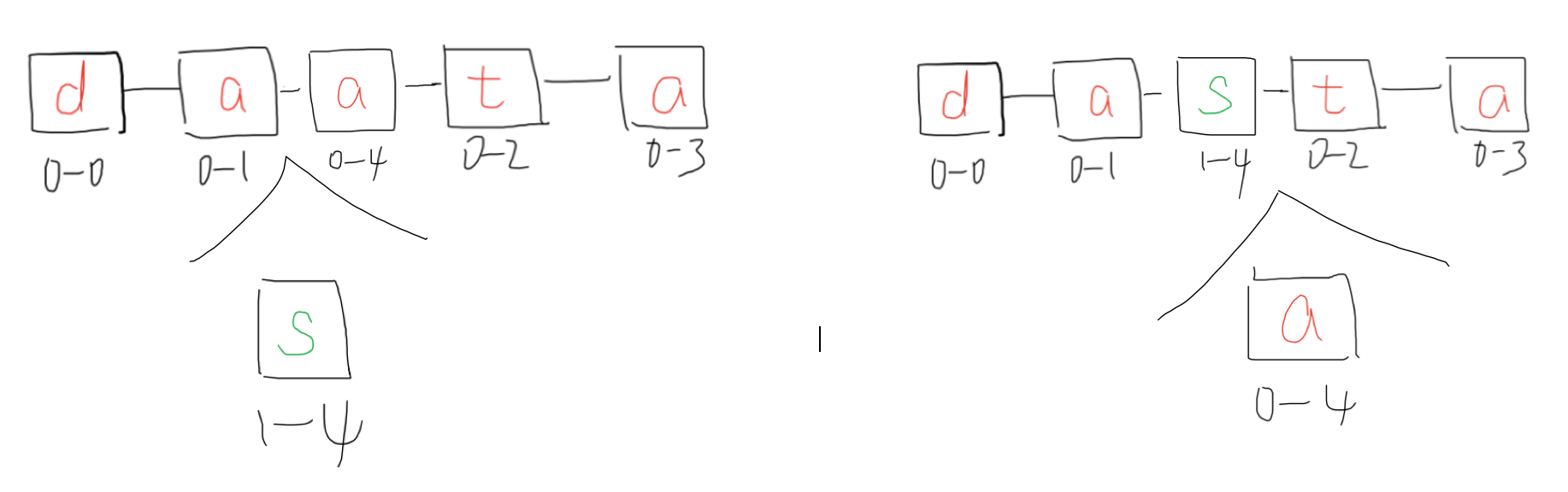 Insertion step 4
Insertion step 4
How to make sure replicas will converge? First, find the previous character_NO then skip the bigger id. There is a deterministic order among each replica when they have same character_NO. inside a document.
In this example, I'll say B > A. 1-4 > 0-1 and 1-4 > 0-4, thus 1-4 is between 0-1 and 0-4. 0-4 > 0-1 and 0-4 < 1-4, then 0-4 should be moved after 1-4.
- Deletion
Deletion is simple because each character is unique through all replica, then we could locate the character and set it to deleted. Why not remove it directly? Let's have an example.
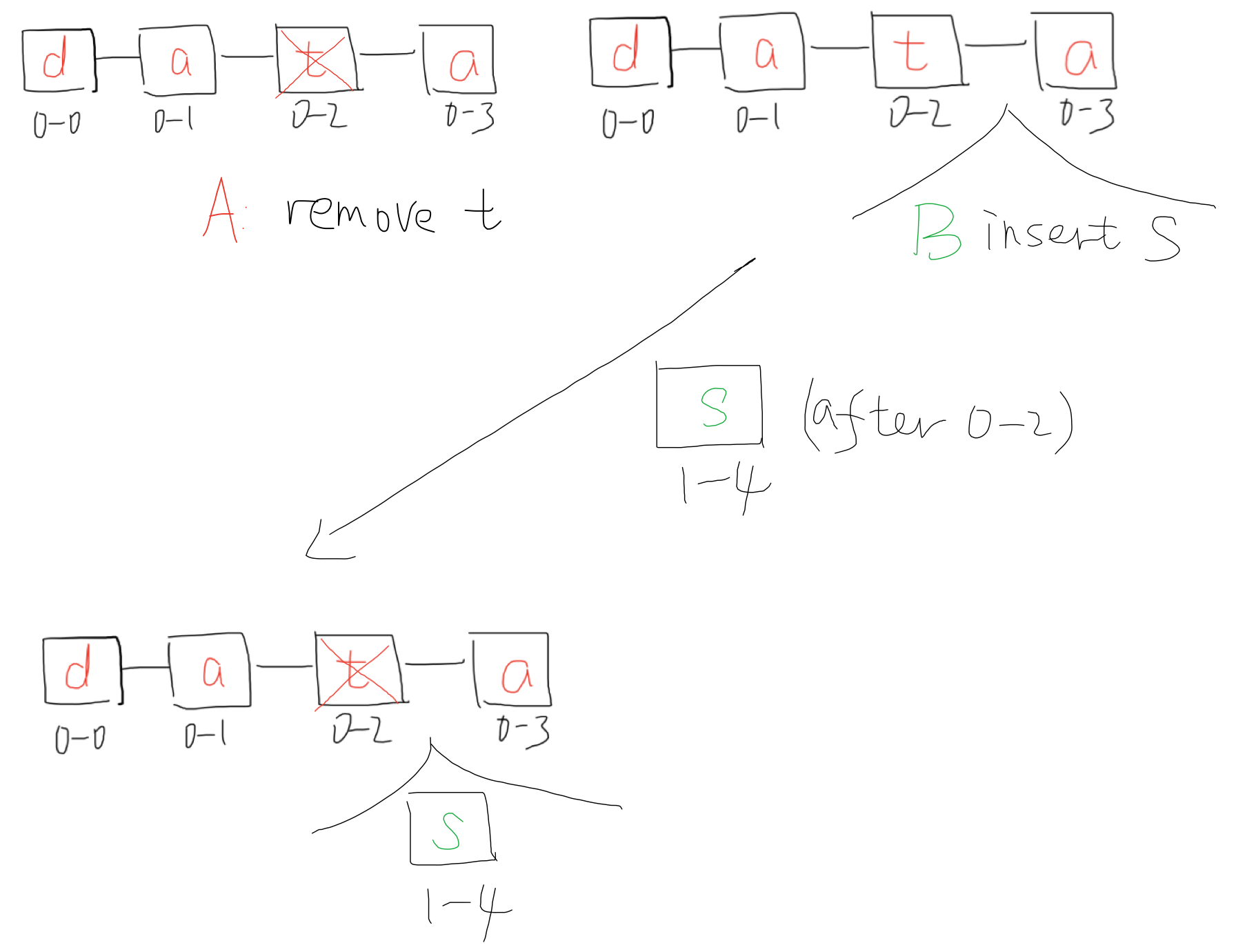 Deletion example
Deletion example
In this case, the operations based on deleted items could still be performed.
My CmRDT model is quite simple and straight forward. The existing issues are slowness caused by linear time operations and space overhead caused by growing meta size.
Please visit here for this CmRDT model.
Reference
- Marc Shapiro, Nuno Pregui¸ca, Carlos Baquero, Marek Zawirski. Conflict-free Replicated Data Types. Xavier D´efago and Franck Petit and Vincent Villain. SSS 2011 - 13th International Symposium Stabilization, Safety, and Security of Distributed Systems, Oct 2011, Grenoble, France. Springer, 6976, pp.386-400, 2011, Lecture Notes in Computer Science
- Hyun-Gul Roh, Myeongjae Jeon, Jin-Soo Kim, and Joonwon Lee. 2011. Replicated abstract data types: Building blocks for collaborative applications. J. Parallel Distrib. Comput. 71, 3 (March 2011), 354-368.
- Codemesh Talk
- Microsoft Research Talk
- Marc Shapiro, Nuno Pregui¸ca, Carlos Baquero, Marek Zawirski. A comprehensive study of Convergent and Commutative Replicated Data Types. RR-7506, Inria – Centre Paris-Rocquencourt; INRIA. 2011, pp.50.
- Chengzheng Sun, Xiaohua Jia, Yanchun Zhang, Yun Yang, and David Chen. 1998. Achieving convergence, causality preservation, and intention preservation in real-time cooperative editing systems. ACM Trans. Comput.-Hum. Interact. 5, 1 (March 1998), 63-108.
- Chengzheng Sun and Clarence Ellis. 1998. Operational transformation in real-time group editors: issues, algorithms, and achievements. In Proceedings of the 1998 ACM conference on Computer supported cooperative work (CSCW '98). ACM, New York, NY, USA, 59-68.
- David Sun, Steven Xia, Chengzheng Sun, and David Chen. 2004. Operational transformation for collaborative word processing. In Proceedings of the 2004 ACM conference on Computer supported cooperative work (CSCW '04). ACM, New York, NY, USA, 437-446.