Binary Indexed Tree
A comprehensive guide to Binary Indexed Trees (BIT), including implementation, analysis, and applications in prefix sum computations.
Background
Before we talk about what is Binary Indexed Tree, let's start from Prefix Sum:
In computer science, the prefix sum, scan, or cumulative sum of a sequence of numbers
,
,
, ... is a second sequence of numbers
,
,
, ..., the sums of prefixes of the input sequence.
Imagine we have an array Array of n elements, Sum(i, j) means we summate from to
where
i < j < n, and clearly the time complexity is O(n) if we add one by one.
Now someone would ask could we do better if this function will be called many times? Sure, after first scan, we compute Sum(0, i) for each i in [0, n) and save the results in Sums array. And next time, if asked Sum(i, j), just return Sums[j] - Sums[i-1] when i != 0 else Sums[j]. Perfect!
Now, someone would ask what if we could update one elements in the array? Re-compute Sums? That would be another O(n) time, it's expensive if it's update-intensive.
You may notice, re-compute the entire array is actually the worst case. Why? If Update(i, x), we could just update Sums[j] when j >= i.
Seems like the performance bottleneck is the number of update times.
Introducing BIT
In order to boost performance, I'm now introducing a new data structure -- Binary Index Tree, as BIT. BIT is also called Fenwick Tree.
Although BIT is a "tree", in practice they are implemented in flat array analogous to binary heap. We will still use the notations from last section.
The intuition is simple, in traditional array, each index only represents its own value. How could we reconstruct the array to make each index represent more than itself? Then to compute each Sums[i], we could add fewer number of indexes to it. Sounds crazy? Let's go back to long long ago, what is an integer.
Each integer can be represented as sum of powers of two. In the same way, cumulative frequency can be represented as sum of sets of subfrequencies.
Still crazy? See what a BIT looks like:
 16 BIT
16 BIT
Soure: Topcoder) Bar shows range of frequencies accumulated in top element
If that is not clear, see the picture below
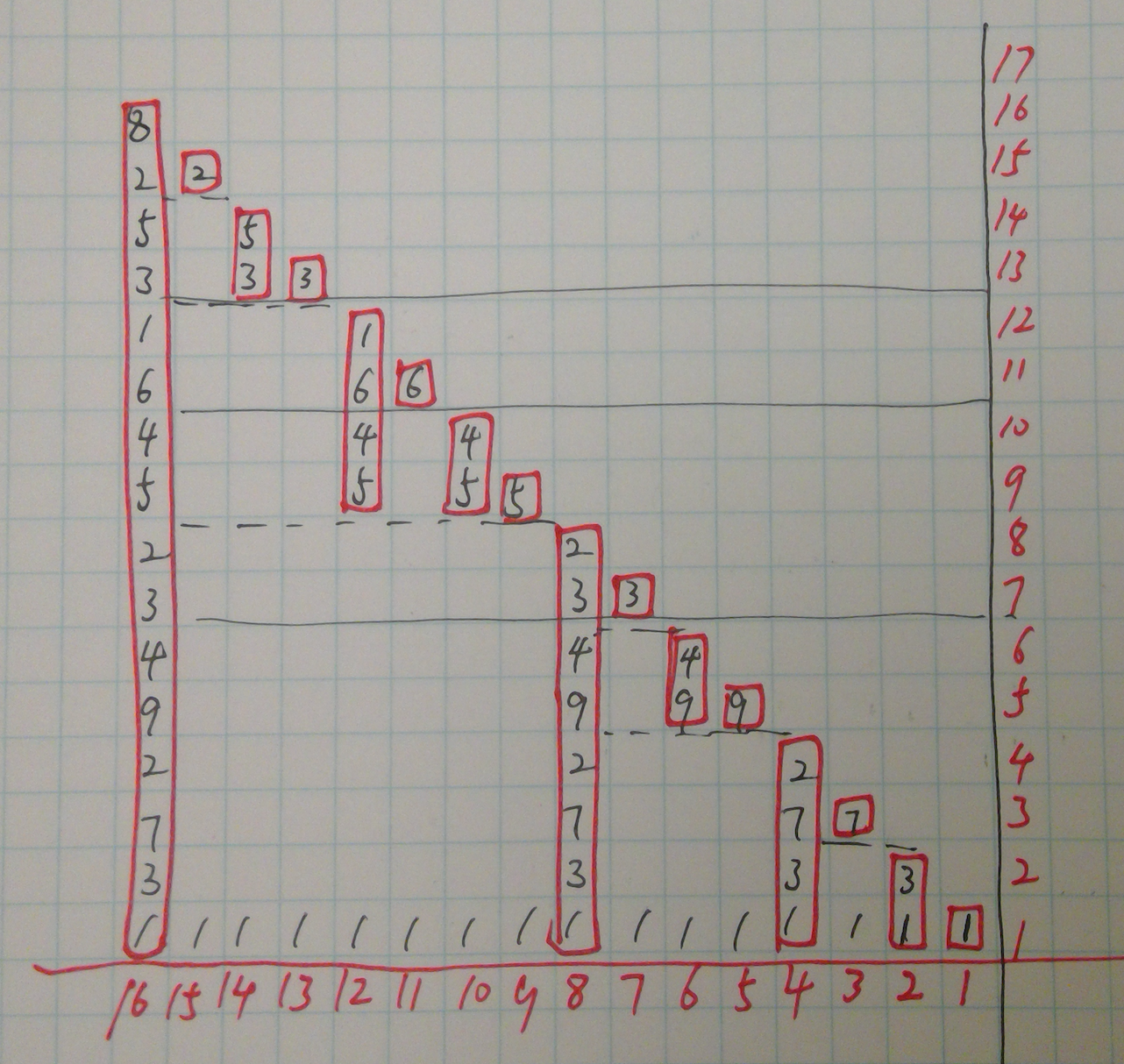 16 BIT The value of a certain index is the summation of all the non-overlapped values in the right including itself
16 BIT The value of a certain index is the summation of all the non-overlapped values in the right including itself
We create a new array tree, obviously, each tree[i] has more values except Array[i].
eg. Sums[13] = tree[13] + tree[12] + tree[8], 13, 12, 8 are the indexes that contribute to Sums[13].
Now, let's translate these indexes into binary representation, Sums[1101] = tree[1101] + tree[1100] + tree[1000].
Try more examples, we will notice that given an index, we need to iteratively get all the non-zero digits from its binary representation. To efficiently isolate the last non-zero digit, we could use bitwise operations:
$$
To get all the indexes contributing to the sum, we could
while x:
x -= x & -x
# add value of tree[x]With the indexes ready, we could easily get all the contributing values to a prefix sum. Therefore, in BIT, the worst time complexity for Sum(i) is O(logn) where n is the maximum value which will have non-zero value. eg. in the 16 elements array((tree)), n in 16.
For update operation of index i, we only need to correspondingly update Sums[j] where j would be the indexes that i will actually contribute to its summation. The indexes to update should be:
while x:
x += x & -x
# update value of tree[x]Similarly, the worst case time complexity of update is O(logn). Go back to the observation we got at the end of last section, in traditional array, we should update as most n time, not its logn!
Note that we will ignore index 0 because it has no contribution to any summation. This is an implementation detail, you should come up with your own design to deal with such corner cases.
Analysis
In our naive version of prefix sum algorithms, Sum and Update operations are fighting with each other, at least one of them will be O(n) time complexity.
In BIT, we could guarantee for both operations, they are O(logn) time complexity in the worst case. Indeed a huge improve!
The best part of BIT is simplicity. 20 lines of code, we can have a nice and clean implementation. The underlying concept is also quite simple, which is understandable for CS newbies!
Multi-dimentional BIT
After understanding the simple version BIT, we could easily extend it to multi-dimentional, an example of 2D BIT:
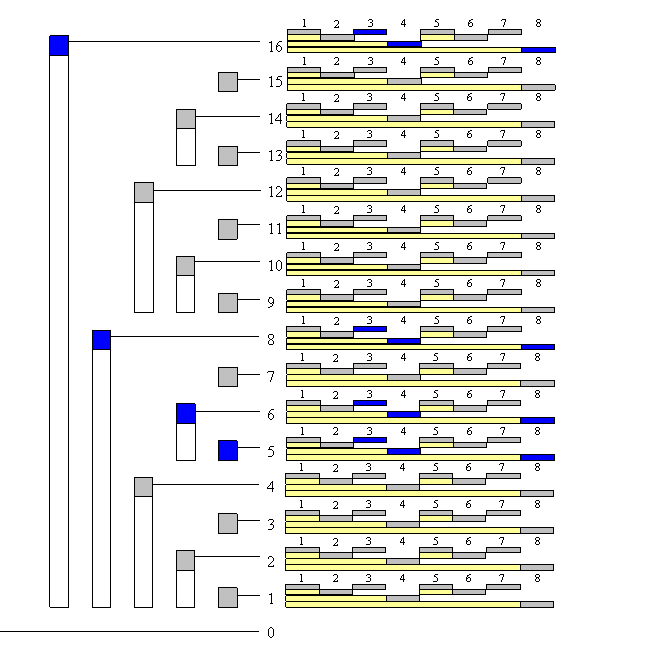 16 BIT
Source: Topcoder BIT is array of arrays, so this is two-dimensional BIT size 16 x 8. Blue fields are fields which we should update when we are updating index ((5 , 3))
16 BIT
Source: Topcoder BIT is array of arrays, so this is two-dimensional BIT size 16 x 8. Blue fields are fields which we should update when we are updating index ((5 , 3))
Except the nested index computation, all the other logic should be the same.
Application
Prefix sum has many applications in computer science, such as parallel algorithms or functional programming. For detailed description, please read here.
With BIT or similar data structure, we could efficiently compute prefix sum.
References
Appendix: My Python implementation
Please star me if you find it useful.
class BIT:
def __init__(self, array):
self.size = len(array)
self.bit = [0] * (self.size+1)
self.array = [0] * self.size
for key, val in enumerate(array):
self.update(key, val)
def __getitem__(self, key):
key += 1
if key > self.size or key < 0:
raise ValueError('index out of range')
res = 0
while key:
res += self.bit[key]
key -= key & -key
return res
def update(self, key, delta):
self.array[key] += delta
key += 1
if key > self.size or key < 0:
raise ValueError('index out of range')
while key < self.size + 1:
self.bit[key] += delta
key += key & -key
def __setitem__(self, key, val):
delta = val - self.array[key]
self.update(key, delta)